













































How AI simplifies data management for drug discovery
Calithera Biosciences is a small, Northern California immunotherapy company with a pipeline of drugs in various stages of premarket development for cancer and cystic fibrosis. Like any manufacturer creating complex new products, Calithera keeps track of lots of data.
But unlike advanced technology companies in other fields, drug discovery companies have the US Food and Drug Administration constantly looking over their shoulders, especially when they’re testing their products on people.
Calithera is running registered clinical trials on its products to study their safety, whether they’re effective in patients with specific gene mutations, and how well they work in combination with other therapies. The company must collect detailed data on hundreds of patients. While some of its trials are in early stages and involve only a small number of patients, others span more than 100 research centers across the globe.
“In the life-sciences world, one of the biggest challenges we have is the enormous amount of data we generate, more than any other business,” says Behrooz Najafi, Calithera’s lead information technology strategist. (Najafi is also chief information and technology officer for health-care tech company Innovio.) Calithera must store and manage the data while making sure it’s readily available when needed, even years from now. It also must comply with specific FDA requirements on how the data is generated, stored, and used.
Even something seemingly as simple as upgrading a file server must follow a strictly defined FDA protocol with multiple testing and review steps. Najafi says all this compliance-related data wrangling can add 30% to 40% to the overhead of a company like his, in both direct cost and hours of staff time. These are resources that could otherwise be put toward more research or other value-added activities.
Calithera has sidestepped much of that additional cost and vastly improved its ability to track its data by putting it in what Najafi calls a secure “storage container,” a protected area for regulated content, part of a larger cloud document management application, largely driven by artificial intelligence. AI never sleeps, never gets bored, and can learn to distinguish among hundreds of different types of documents and forms of data.
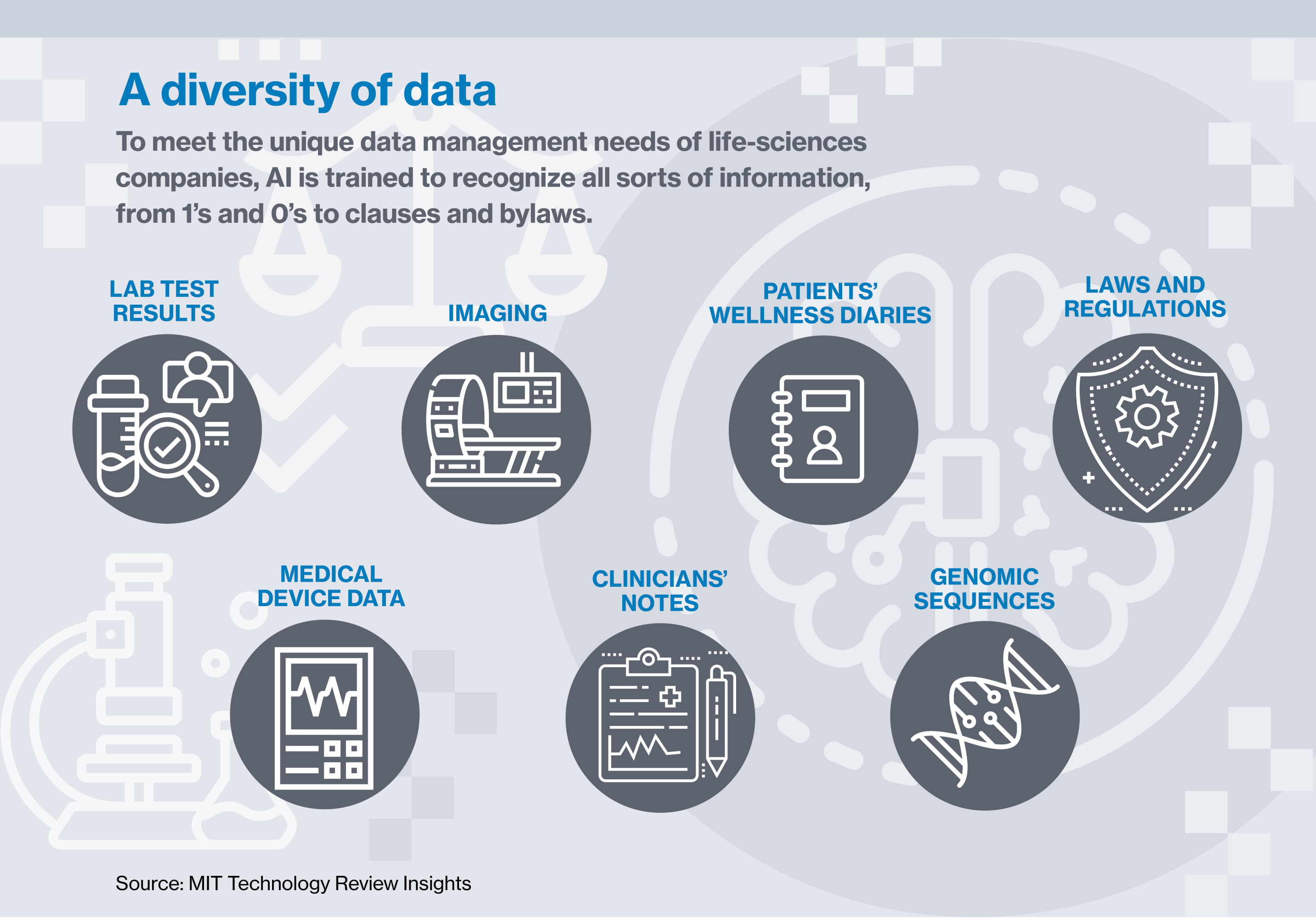
Here’s how it works: clinical or patient data is put into the system and scanned by AI, which recognizes specific features that pertain to accuracy, completeness, compliance with regulations, and other aspects of the data. AI can flag when there’s a missing test result, or when a patient hasn’t submitted a required diary entry. It knows who’s allowed to access certain types of data and what they are and are not allowed to do with it. It can detect ransomware attacks and head them off. And it can automatically document all that to the satisfaction of the FDA or any other regulatory body.
“This approach takes the compliance burden off of us,” Najafi says. Once data from its many research sites is in the platform, Calithera knows that the AI will make sure it’s safe, complete, and compliant with all regulations, and will flag any problems.
Managing drug discovery data to comply with the needs of research and the requirements of regulators can be, as Najafi observes, onerous and expensive. The life-sciences industry can borrow data management techniques and platforms developed for other industries, but they must be modified to handle the levels of security and validation, and the detailed audit trails, that are a way of life for drug developers. AI can streamline these tasks, improving the security, consistency, and validity of data—freeing up overhead for drug companies and research organizations to apply to their core mission.

An intricate data management environment
Regulatory compliance helps ensure that new drugs and devices are safe and work as intended. It also protects the privacy and personal information of the thousands of patients who participate in clinical trials and post-market research. No matter their size—enormous global conglomerates or tiny startups trying to get a single product to market—drug developers must adhere to the same standard practices to document, audit, validate, and protect every shred of information connected with a clinical trial.
When researchers run a double-blind study, the gold standard for proving the efficacy of a drug, they have to keep patients’ information anonymous. But they must easily de-anonymize the data later, making it identifiable, so patients in the control group can receive the test drug, and so the company can track—sometimes for years— how the product performs in real-world use.
The data management burden falls hard on emerging and midsize biosciences companies, says Ramin Farassat, chief strategy and product officer at Egnyte, a Silicon Valley software company that makes and supports the AI-enabled data management platform used by Calithera and several hundred other life-sciences companies.
“This approach takes the compliance burden off of us,” Najafi says. Once data from its many research sites is in the platform, Calithera knows that the AI will make sure it’s safe, complete, and compliant with all regulations, and will flag any problems.
Download the full report.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.