High-quality data enables medical research
One unexpected side effect of the covid-19 pandemic was that the usually obscure world of health data was brought to national attention. Who was most at risk for infection? Who was most likely to die? Was one treatment better than another? Was getting covid-19 more or less dangerous than getting a vaccine?

These complex questions, usually the province of medical research, became concrete seemingly overnight. While amateur epidemiologists scoured the internet for statistics to support their personal beliefs, professionals often appeared on the nightly news, even if just to say, “We don’t have good enough data.”
While our focus on the pandemic has now subsided, our health data quality problems remain. We’re swimming in health data—by some estimates, one-third of all data generated in the world is related to health and health care, and that amount increases more than 30% every year.
With all that data, then, why can’t we answer our most pressing heath questions? Which of the five top diabetes drugs (if any) will be best for me? Will back surgery be more effective than physical therapy for my spine? What are the chances that I will need chemotherapy in addition to radiation to make my tumor go away?
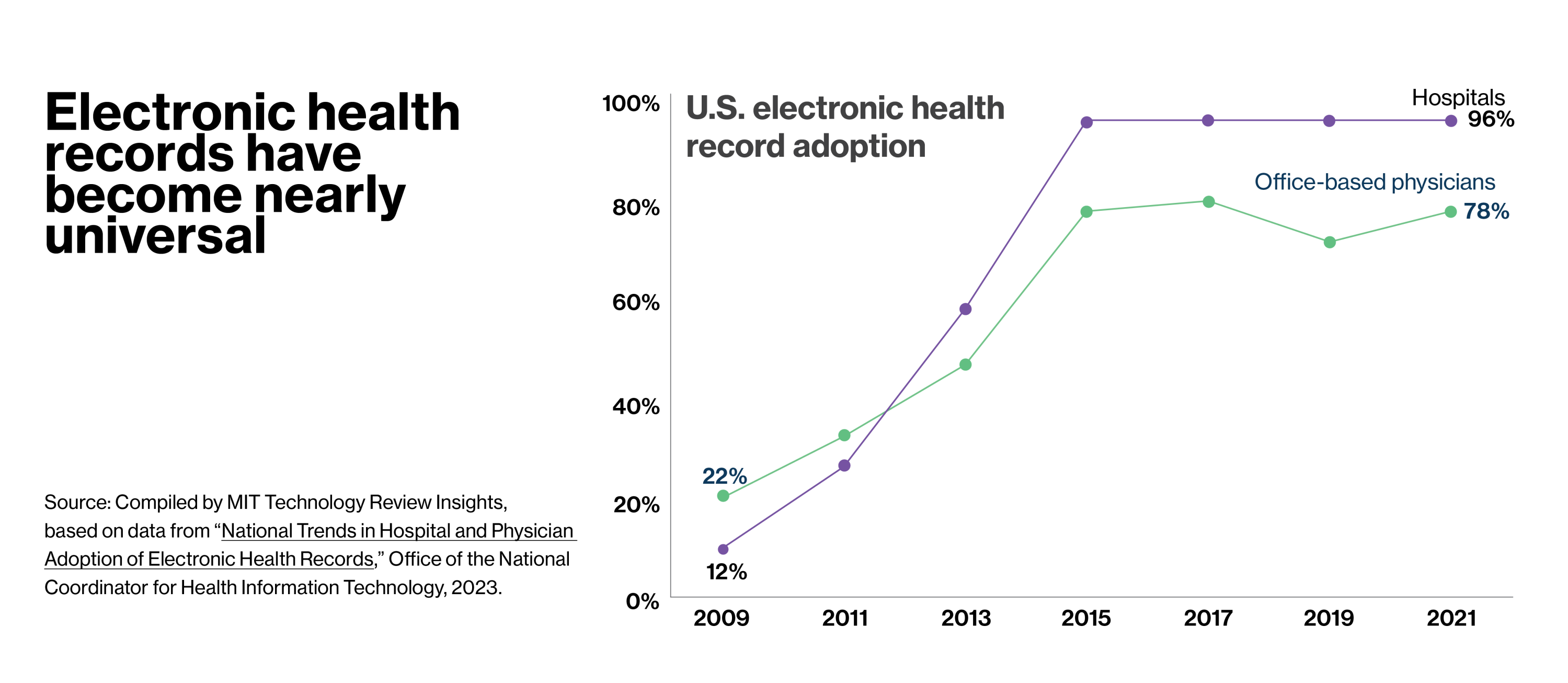
EHRs have become ubiquitous
Electronic health records (EHRs) have become pervasive in the U.S., largely thanks to a multi-billion-dollar federal initiative that made interoperable EHRs a national goal. The 2009 HITECH Act provided incentives for healthcare providers who computerized and penalties for those who did not. In addition to the improved patient care this would enable, the millions of digitized health records would create opportunities to transform medical research.
“Prior to EHRs, clinical research was all on paper,” says Dale Sanders, chief strategy officer at Intelligent Medical Objects (IMO), a healthcare data enablement company that offers clinical terminology and tooling to improve the quality of medical data. “You would transfer that paper-based data to spreadsheets and do your own data analysis in a very small local environment. It didn’t give a broader view of a patient’s life, and it certainly didn’t enable any kind of broader population analysis.”
Theoretically, EHRs should make it possible to aggregate, analyze, and search through information collected from millions of patients to discover patterns that aren’t evident on a smaller scale—as well as to track a single patient’s health status methodically over time. Imagine being able to quickly compare and analyze the cases of the few thousand people who have a particular rare condition or to follow users of a certain drug over a set period of time to observe long-term side effects that weren’t obvious in trials.

Of course, it’s not that easy. “There’s a lot of raw data [in EHRs] and it’s very, very dirty,” explains John Lee, MD, an emergency physician and clinical informaticist who has served as chief medical information officer for several health systems. “Some of it isn’t accurate, and the stuff that is accurate isn’t packaged up in a way that’s usable and scalable. There is an opportunity tantalizingly at our fingertips if we could get out of our own way.”
Sanders concurs. “Covid made us all realize that the data that we’re collecting with EHRs is not very good for clinical research, or for reacting to pandemics and public health challenges. It’s time to evolve the way we’re using them.”
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.