Everyone in AI is talking about Manus. We put it to the test.
Since the general AI agent Manus was launched last week, it has spread online like wildfire. And not just in China, where it was developed by the Wuhan-based startup Butterfly Effect. It’s made its way into the global conversation, with influential voices in tech, including Twitter cofounder Jack Dorsey and Hugging Face product lead Victor Mustar, praising its performance. Some have even dubbed it “the second DeepSeek,” comparing it to the earlier AI model that took the industry by surprise for its unexpected capabilities as well as its origin.
Manus claims to be the world’s first general AI agent, using multiple AI models (such as Anthropic’s Claude 3.5 Sonnet and fine-tuned versions of Alibaba’s open-source Qwen) and various independently operating agents to act autonomously on a wide range of tasks. (This makes it different from AI chatbots, including DeepSeek, which are based on a single large language model family and are primarily designed for conversational interactions.)
Despite all the hype, very few people have had a chance to use it. Currently, under 1% of the users on the wait list have received an invite code. (It’s unclear how many people are on this list, but for a sense of how much interest there is, Manus’s Discord channel has more than 186,000 members.)
MIT Technology Review was able to obtain access to Manus, and when I gave it a test-drive, I found that using it feels like collaborating with a highly intelligent and efficient intern: While it occasionally lacks understanding of what it’s being asked to do, makes incorrect assumptions, or cuts corners to expedite tasks, it explains its reasoning clearly, is remarkably adaptable, and can improve substantially when provided with detailed instructions or feedback. Ultimately, it’s promising but not perfect.
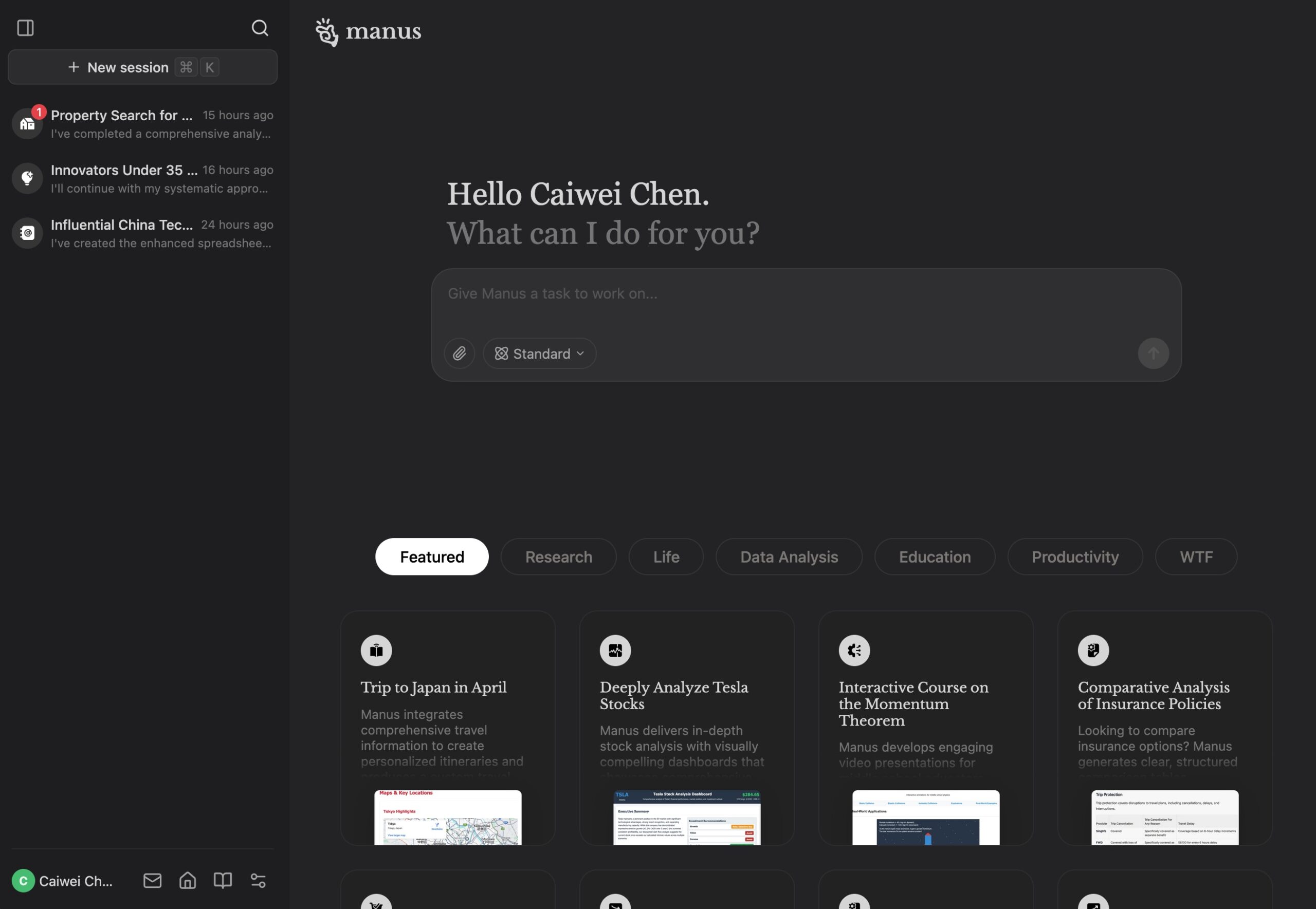
Just like its parent company’s previous product, an AI assistant called Monica that was released in 2023, Manus is intended for a global audience. English is set as the default language, and its design is clean and minimalist.
To get in, a user has to enter a valid invite code. Then the system directs users to a landing page that closely resembles those of ChatGPT or DeepSeek, with previous sessions displayed in a left-hand column and a chat input box in the center. The landing page also features sample tasks curated by the company—ranging from business strategy development to interactive learning to customized audio meditation sessions.
Like other reasoning-based agentic AI tools, such as ChatGPT DeepResearch, Manus is capable of breaking tasks down into steps and autonomously navigating the web to get the information it needs to complete them. What sets it apart is the “Manus’s Computer” window, which allows users not only to observe what the agent is doing but also to intervene at any point.
To put it to the test, I gave Manus three assignments: (1) compile a list of notable reporters covering China tech, (2) search for two-bedroom property listings in New York City, and (3) nominate potential candidates for Innovators Under 35, a list created by MIT Technology Review every year.
Here’s how it did:
Task 1: The first list of reporters that Manus gave me contained only five names, with five “honorable mentions” below them. I noticed that it listed some journalists’ notable work but didn’t do this for others. I asked Manus why. The reason it offered was hilariously simple: It got lazy. It was “partly due to time constraints as I tried to expedite the research process,” the agent told me. When I insisted on consistency and thoroughness, Manus responded with a comprehensive list of 30 journalists, noting their current outlet and listing notable work. (I was glad to see I made the cut, along with many of my beloved peers.)
I was impressed that I was able to make top-level suggestions for changes, much as someone would with a real-life intern or assistant, and that it responded appropriately. And while it initially overlooked changes in some journalists’ employer status, when I asked it to revisit some results, it quickly corrected them. Another nice feature: The output was downloadable as a Word or Excel file, making it easy to edit or share with others.
Manus hit a snag, though, when accessing journalists’ news articles behind paywalls; it frequently encountered captcha blocks. Since I was able to follow along step by step, I could easily take over to complete these, though many media sites still blocked the tool, citing suspicious activity. I see potential for major improvements here—and it would be useful if a future version of Manus could proactively ask for help when it encounters these sorts of restrictions.
Task 2: For the apartment search, I gave Manus a complex set of criteria, including a budget and several parameters: a spacious kitchen, outdoor space, access to downtown Manhattan, and a major train station within a seven-minute walk. Manus initially interpreted vague requirements like “some kind of outdoor space” too literally, completely excluding properties without a private terrace or balcony access. However, after more guidance and clarification, it was able to compile a broader and more helpful list, giving recommendations in tiers and neat bullet points.
The final output felt straight from Wirecutter, containing subtitles like “best overall,” “best value,” and “luxury option.” This task (including the back-and-forth) took less than half an hour—a lot less time than compiling the list of journalists (which took a little over an hour), likely because property listings are more openly available and well-structured online.
Task 3: This was the largest in scope: I asked Manus to nominate 50 people for this year’s Innovators Under 35 list. Producing this list is an enormous undertaking, and we typically get hundreds of nominations every year. So I was curious to see how well Manus could do. It broke the task into steps, including reviewing past lists to understand selection criteria, creating a search strategy for identifying candidates, compiling names, and ensuring a diverse selection of candidates from all over the world.
Developing a search strategy was the most time-consuming part for Manus. While it didn’t explicitly outline its approach, the Manus’s Computer window revealed the agent rapidly scrolling through websites of prestigious research universities, announcements of tech awards, and news articles. However, it again encountered obstacles when trying to access academic papers and paywalled media content.
After three hours of scouring the internet—during which Manus (understandably) asked me multiple times whether I could narrow the search—it was only able to give me three candidates with full background profiles. When I pressed it again to provide a complete list of 50 names, it eventually generated one, but certain academic institutions and fields were heavily overrepresented, reflecting an incomplete research process. After I pointed out the issue and asked it to find five candidates from China, it managed to compile a solid five-name list, though the results skewed toward Chinese media darlings. Ultimately, I had to give up after the system warned that Manus’s performance might decline if I kept inputting too much text.
My assessment: Overall, I found Manus to be a highly intuitive tool suitable for users with or without coding backgrounds. On two of the three tasks, it provided better results than ChatGPT DeepResearch, though it took significantly longer to complete them. Manus seems best suited to analytical tasks that require extensive research on the open internet but have a limited scope. In other words, it’s best to stick to the sorts of things a skilled human intern could do during a day of work.
Still, it’s not all smooth sailing. Manus can suffer from frequent crashes and system instability, and it may struggle when asked to process large chunks of text. The message “Due to the current high service load, tasks cannot be created. Please try again in a few minutes” flashed on my screen a few times when I tried to start new requests, and occasionally Manus’s Computer froze on a certain page for a long period of time.
It has a higher failure rate than ChatGPT DeepResearch—a problem the team is addressing, according to Manus’s chief scientist, Peak Ji. That said, the Chinese media outlet 36Kr reports that Manus’s per-task cost is about $2, which is just one-tenth of DeepResearch’s cost. If the Manus team strengthens its server infrastructure, I can see the tool becoming a preferred choice for individual users, particularly white-collar professionals, independent developers, and small teams.
Finally, I think it’s really valuable that Manus’s working process feels relatively transparent and collaborative. It actively asks questions along the way and retains key instructions as “knowledge” in its memory for future use, allowing for an easily customizable agentic experience. It’s also really nice that each session is replayable and shareable.
I expect I will keep using Manus for all sorts of tasks, in both my personal and professional lives. While I’m not sure the comparisons to DeepSeek are quite right, it serves as further evidence that Chinese AI companies are not just following in the footsteps of their Western counterparts. Rather than just innovating on base models, they are actively shaping the adoption of autonomous AI agents in their own way.
