Architecting cloud data resilience
Cloud has become a given for most organizations: according to PwC’s 2023 cloud business survey, 78% of companies have adopted cloud in most or all parts of the business. These companies have migrated on-premises systems to the cloud seeking faster time to market, greater scalability, cost savings, and improved collaboration.

Yet while cloud adoption is widespread, research by McKinsey shows that companies’ concerns around the resiliency and reliability of cloud operations, coupled with an ever-evolving regulatory environment, are limiting their ability to derive full value from the cloud. As the value of a business’s data grows ever clearer, the stakes of making sure that data is resilient are heightened. Business leaders now justly fear that they might run afoul of mounting data regulations and compliance requirements, that bad actors might target their data in a ransomware attack, or that an operational disruption affecting their data might grind the entire business to a halt.
For all its competitive advantages, moving to the cloud presents unique challenges for data resilience. In fact, the qualities of cloud that make it so appealing to businesses—scalability, flexibility, and the ability to handle rapidly changing data—are the same ones that make it challenging to ensure the resilience of mission-critical applications and their data in the cloud.
“A widely held misconception is that the durability of the cloud automatically protects your data,” says Rick Underwood, CEO of Clumio, a backup and recovery solutions provider. “But a multitude of factors in cloud environments can still reach your data and wipe it out, maliciously encrypt it, or corrupt it.”
Complicating matters is that moving data to the cloud can lead to reduced data visibility, as individual teams begin creating their own instances and IT teams may not be able to see and track all the organization’s data. “When you make copies of your data for all of these different cloud services, it’s very hard to keep track of where your critical information goes and what needs to be compliant,” says Underwood. The result, he adds, is a “Wild West in terms of identifying, monitoring, and gaining overall visibility into your data in the cloud. And if you can’t see your data, you can’t protect it.”
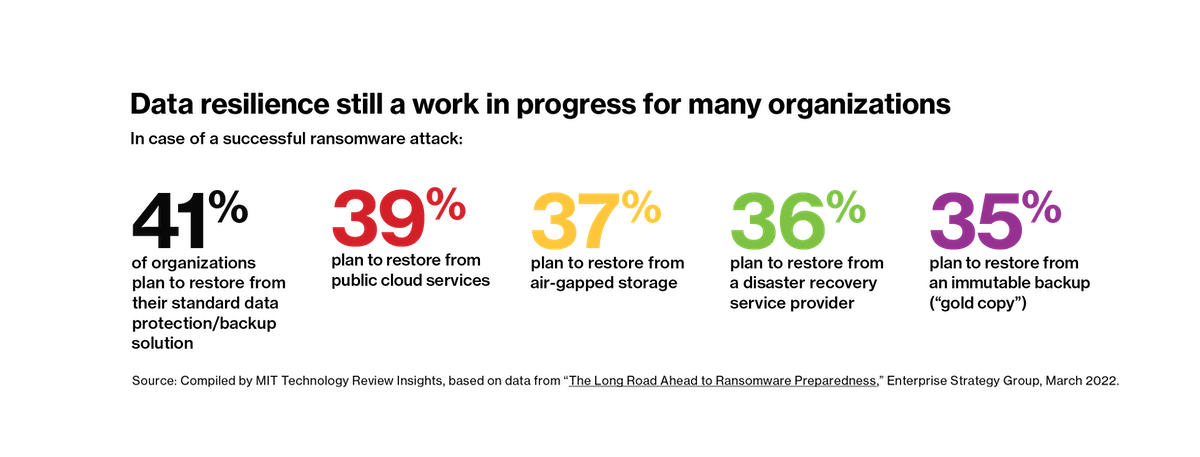
The end of traditional backup architecture
Until recently, many companies relied on traditional backup architectures to protect their data. But the inability of these backup systems to handle vast volumes of cloud data—and scale to accommodate explosive data growth—is becoming increasingly evident, particularly to cloud-native enterprises. In addition to issues of data volume, many traditional backup systems are ill-equipped to handle the sheer variety and rate of change of today’s enterprise data.
In the early days of cloud, Steven Bong, founder and CEO of AuditFile, had difficulty finding a backup solution that could meet his company’s needs. AuditFile supplies audit software for certified public accountants (CPAs) and needed to protect their critical and sensitive audit work papers. “We had to back up our data somehow,” he says. “Since there weren’t any elegant solutions commercially available, we had a home-grown solution. It was transferring data, backing it up from different buckets, different regions. It was fragile. We were doing it all manually, and that was taking up a lot of time.”
Frederick Gagle, vice president of technology for BioPlus Specialty Pharmacy, notes that backup architectures that weren’t designed for cloud don’t address the unique features and differences of cloud platforms. “A lot of backup solutions,” he says, “started off being on-prem, local data backup solutions. They made some changes so they could work in the cloud, but they weren’t really designed with the cloud in mind, so a lot of features and capabilities aren’t native.”
Underwood agrees, saying, “Companies need a solution that’s natively architected to handle and track millions of data operations per hour. The only way they can accomplish that is by using a cloud-native architecture.”
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.
