An E. coli biocomputer solves a maze by sharing the work
E. coli thrives in our guts, sometimes to unfortunate effect, and it facilitates scientific advances—in DNA, biofuels, and Pfizer’s covid vaccine, to name but a few. Now this multitalented bacterium has a new trick: it can solve a classic computational maze problem using distributed computing—dividing up the necessary calculations among different types of genetically engineered cells.
This neat feat is a credit to synthetic biology, which aims to rig up biological circuitry much like electronic circuitry and to program cells as easily as computers.
The maze experiment is part of what some researchers consider a promising direction in the field: rather than engineering a single type of cell to do all the work, they design multiple types of cells, each with different functions, to get the job done. Working in concert, these engineered microbes might be able to “compute” and solve problems more like multicellular networks in the wild.
So far, for better or worse, fully harnessing biology’s design power has eluded, and frustrated, synthetic biologists. “Nature can do this (think about a brain), but we don’t yet know how to design at that overwhelming level of complexity using biology,” says Pamela Silver, a synthetic biologist at Harvard.
The study with E. coli as maze solvers, led by biophysicist Sangram Bagh at the Saha Institute of Nuclear Physics in Kolkata, is a simple and fun toy problem. But it also serves as a proof of principle for distributed computing among cells, demonstrating how more complex and practical computational problems might be solved in a similar way. If this approach works at larger scales, it could unlock applications pertaining to everything from pharmaceuticals to agriculture to space travel.
“As we move into solving more complex problems with engineered biological systems, spreading out the load like this is going to be an important capacity to establish,” says David McMillen, a bioengineer at the University of Toronto.
How to build a bacterial maze
Getting E. coli to solve the maze problem involved some ingenuity. The bacteria didn’t wander through a palace labyrinth of well-pruned hedges. Rather, the bacteria analyzed various maze configurations. The setup: one maze per test tube, with each maze generated by a different chemical concoction.
The chemical recipes were abstracted from a 2 × 2 grid representing the maze problem. The grid’s top left square is the start of the maze, and the bottom right square is the destination. Each square on the grid can be either an open path or blocked, yielding 16 possible mazes.
Bagh and his colleagues mathematically translated this problem into a truth table composed of 1s and 0s, showing all possible maze configurations. Then they mapped those configurations onto 16 different concoctions of four chemicals. The presence or absence of each chemical corresponds to whether a particular square is open or blocked in the maze.
The team engineered multiple sets of E. coli with different genetic circuits that detected and analyzed those chemicals. Together, the mixed population of bacteria functions as a distributed computer; each of the various sets of cells perform part of the computation, processing the chemical information and solving the maze.
Running the experiment, the researchers first put the E. coli in 16 test tubes, added a different chemical-maze concoction in each, and left the bacteria to grow. After 48 hours, if the E. coli detected no clear path through the maze—that is, if the requisite chemicals were absent—then the system remained dark. If the correct chemical combination was present, corresponding circuits turned “on” and the bacteria collectively expressed fluorescent proteins, in yellow, red, blue or pink, to indicate solutions. “If there is a path, a solution, the bacteria glow,” says Bagh.
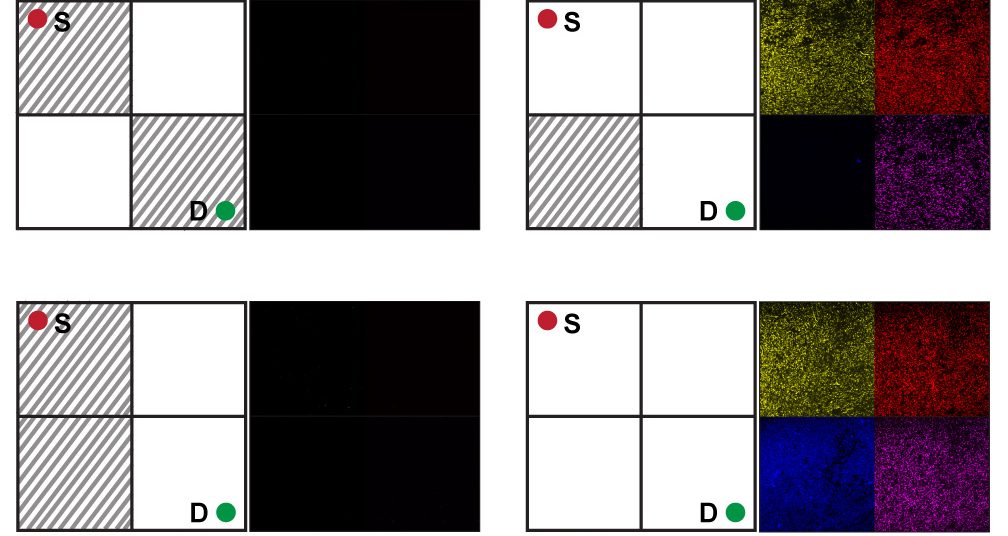
What Bagh found particularly exciting was that in churning through all 16 mazes, the E. coli provided physical proof that only three were solvable. “Calculating this with a mathematical equation is not straightforward,” Bagh says. “With this experiment, you can visualize it very simply.”
Lofty goals
Bagh envisions such a biological computer helping in cryptography or steganography (the art and science of hiding information), which use mazes to encrypt and conceal data, respectively. But the implications extend beyond those applications to synthetic biology’s loftier ambitions.
The idea of synthetic biology dates to the 1960s, but the field emerged concretely in 2000 with the creation of synthetic biological circuits (specifically, a toggle switch and an oscillator) that made it increasingly possible to program cells to produce desired compounds or react intelligently within their environments.
Biology, however, has not been the most cooperative of collaborators. One limiting factor is how many changes you can make to a cell without destroying its viability. “The cell has its own interests,” says McMillen, whose lab is developing a yeast-based system that detects malaria antibodies in blood samples and a similar system for covid. When inserting human-designed components into a biological system, he says, “you’re fighting against natural selection and entropy, which are two of the biggies in terms of forces of nature.”
If a cell is overloaded with too many doodads, for instance, there’s risk of interference and crosstalk—hindering performance and limiting the system’s capabilities. With the computational maze solvers, Bagh says, the algorithm could have been programmed into only one type of E. coli cell. But the system ran best when the necessary circuit functions were distributed among six types of cells.
“There is a physical limit on how many genetic parts can be used in a single cell,” says Karen Polizzi, a chemical engineer at Imperial College London, who develops cellular biosensors to monitor the manufacture of therapeutic proteins and vaccines. “This limits the sophistication of the computing concepts that can be developed.”
“Distributed computing might actually be a way to achieve some of [synthetic biology’s] really lofty goals,” she adds. “Because there’s no way you’re going to get a cell to completely do a complex task by itself.”
Cellular supremacy
Chris Voigt, a synthetic biologist at MIT (and editor in chief of ACS Synthetic Biology, which published Bagh’s result), believes distributed computing is the direction that synthetic biology needs to go.
In Voigt’s view, grand ambitions for microbial cells are justified—and he’s run calculations to back that up. “One teaspoon of bacteria has more logic gates in it than, I think, 2 billion Xeon processors,” he says. “And it has more memory in the DNA than the entire internet. Biology has incredible computing capacity, and it does it by distributing it over an enormous number of cells.” But there are caveats: “A gate takes 20 minutes to process, so it’s very slow.”
Last year, Voigt and collaborators succeeded in programming DNA with a calculator’s algorithm and generating a digital display with fluorescing E. coli. They used software created by Voigt’s lab, called Cello. Cello takes files from Verilog—a programming language used to describe and model circuits—and converts them into DNA, so the same sorts of configurations can be run in cells. All the circuitry for the E. coli calculator, however, was crammed into a single type of cell, a single colony. “We’ve kind of hit the limitation on that,” he admits. “We need to figure out how to make larger designs.”
Even if researchers wanted to run something as low-fi by today’s standards as the Apollo 11 guidance systems in bacteria, Voigt says, it couldn’t be done in a single engineered cell. “The capacity is there,” he says. “We just need ways to break up the algorithm across cells and then link cells up to efficiently share information so that they can collectively perform the calculation.”
Indeed, Voigt questions whether directly mimicking traditional electronic computing is the best approach for harnessing biology’s computational power and solving complex bio-based problems.
In his search for the right approach, Bagh also recently devised a type of artificial neural network architecture for bacterial hardware. And he’s interested in exploring an approach that involves “fuzzy logic,” going beyond the constraints of binary 0s and 1s toward a continuum more aligned with the noise and mess of living biological systems.
Synthetic biologist Ángel Goñi-Moreno, at the Technical University of Madrid, is thinking along similar lines. “If we are going to play with living technology, we need to play by the rules of living systems,” he says.
Goñi-Moreno imagines breaking with the electronic circuit analogy by capitalizing on how cells sense and respond and adapt to their environment, using natural selection itself as a tool to push computational designs along. Evolution, he says, is a biological process that computes information over time, optimizing cellular systems to accomplish a diversity of tasks.
Goñi-Moreno believes this approach could ultimately culminate in what he calls “cellular supremacy.” The term draws a deliberate parallel with “quantum supremacy” (now sometimes called “quantum primacy”)—the point at which quantum computers exceed the capabilities of conventional computing in certain domains. Biocomputers that have evolved to such an extent, Goñi-Moreno says, might offer superior problem-solving savvy in areas such as enhancing agricultural production (think soil bacteria that can adjust the chemicals they make based shifting conditions) and targeting disease therapeutics.
Just don’t expect E. coli to help surf the internet or crack the P vs. NP problem—for that, we’ll still need good old-fashioned computers.